7 複雑さ¶
- ここで、Rescher, N. (1998). Complexity: A philosophical overviewに基づいて複雑さについて考えます。
- 複雑の定義には合意がなく、言語で適切に表現できません。
- 複雑さを測定する「道具」がありません(物語の複雑さと機械の複雑さをどう比べるか)。
- 複雑は単純の反対であると言うことはできます。
- 単純さは効率、複雑さは豊富さに関係していて、単純さは、構造や操作の効率、整然性、複雑さは、錯綜、不調和に関係しています。
- 複雑さにはランダム性があり、法則性がありません。
認識に関するモード
- 記述的複雑性: 当該システムを説明する上で必要な説明の長さ
- 生成的複雑性: 当該システムを作る上で必要な指示の長さ
- 計算的複雑性: 問題を解決する上で必要な時間と労力
存在に関するモード
組成に関する複雑性
構成上の複雑性: 構成素の数
分類上の複雑性: 構成素の種類数
構造に関する複雑性
組織の複雑性: 構成素を組み合わせにおける可能な組み合わせ
階層の複雑性: 統率・従属関係の精巧さ、あるまとまりが下位範疇に分割できること
機能に関する複雑性
操作的複雑性: 操作の豊富さ。機能の種類数
習慣的複雑性: 当該の事象を支配する法則の精緻さ
この中で、(言語そのものではなく)文の複雑性を考える上で、考慮できるのは、構成上の複雑性、分類上の複雑性、階層の複雑性です。
以下の1から7の図で考えてみましょう。
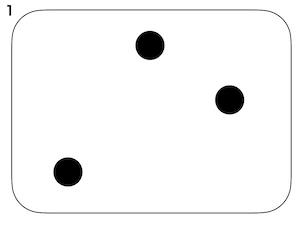

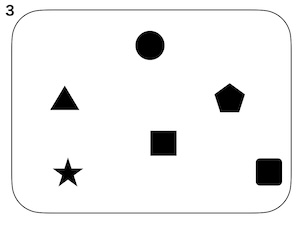
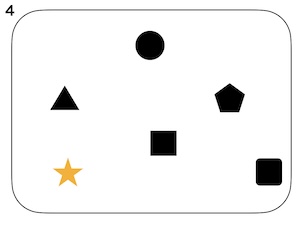
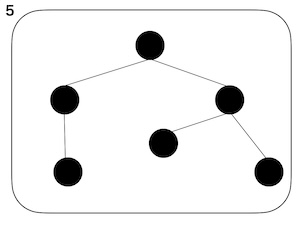
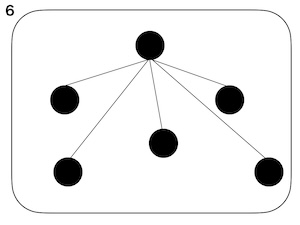

上の図のひとつのまとまりを文、構成素(⚫︎)を語と考えます。
- 構成上の複雑性: 1と2の違い。1に比べて2は構成素の数が多い。
- 分類上の複雑性: 2と3の違い。2に比べて3は構成素の種類数が多い。
- 階層の複雑性: 5と6の違い。階層構造の違い。
上記に加えて、以下の違いも考えられます。
- 3と4の違い。4には大きく異なるものが含まれている。便宜上、ここではdiversityと呼びます。
- 6と7の違い。繋がりの種類数の違い。便宜上ここではtypes of connectionと呼びます。
これらを実際の文の分析に当てはめると次のようになります。
- 構成上の複雑性: 単語の数
- 分類上の複雑性: 単語の種類、品詞の種類
- 階層の複雑性: これまで扱ってきた、木の深さ、木の平坦さなど。
- 以下の2つの文のdiversityを測定してみます。
- Harrison got very excited when his parents gave him a car.
- Carley went shopping for a dress today.
- 便宜上、British National Corpus (BNC)における単語の頻度の逆数をdiversityの指標とします。
- 頻度の高い単語のdiversity指標の値は小さく、頻度が低い単語のdiversity指標の値は大きくなります。
- 文を構成する単語それぞれでdiversity指標を算出し、平均したものを文のdiversity指標とします。
- BNCにない単語はカウントしません。
In [1]:
# British National Corpusの頻度データ読み込み
import pandas as pd
df_bnc = pd.read_csv("../DATA01/BNC.csv",index_col=0)
df_bnc.head()
Out[1]:
| Word | Pos | Rank | Freq | |
|---|---|---|---|---|
| ID0000 | a | det | 5 | 2186369 |
| ID0001 | abandon | v | 2107 | 4249 |
| ID0002 | abbey | n | 5204 | 1110 |
| ID0003 | ability | n | 966 | 10468 |
| ID0004 | able | a | 321 | 30454 |
In [2]:
import spacy
nlp = spacy.load("en_core_web_sm")
In [3]:
text = "Harrison got very excited when his parents gave him a car"
doc = nlp(text)
Div = []
n = 0
for token in doc:
w = token.lemma_
if not df_bnc[df_bnc["Word"] == w].empty:
n += 1
d = 1000/min(df_bnc[df_bnc["Word"] == w]["Freq"].values)
Div.append(d)
float(d/n)
Out[3]:
0.031545741324921134
In [4]:
text = "Carley went shopping for a dress today"
doc = nlp(text)
Div = []
n = 0
for token in doc:
w = token.lemma_
if not df_bnc[df_bnc["Word"] == w].empty:
n += 1
d = 1000/min(df_bnc[df_bnc["Word"] == w]["Freq"].values)
Div.append(d)
float(d/n)
Out[4]:
0.006466214031684449
演習問題15¶
../DATA01/sentences.txtの各文において、diversityを計算し、この中から最大のdiversityを持つ文と最小のdiversityを持つ文を表示してみましょう。