ブートストラップ¶
- データから復元抽出という方法でデータのサンプリングを行う方法。
- 例えば、データが24個あって、AからZのインデックスが付与されているとします。
- このデータからブートストラップで、1組が5つのデータで構成されている3組のサンプルを抽出すると以下のようになります。
第1組: A,H,T,U,W,W
第2組: F,H,G,M,N,P
第3組: Q,R,S,S,S
- データをひとつ選んでサンプルの袋に入れて、元のデータの袋から取り出したデータを復元するので復元抽出と言います。
ブースティング¶
- 複数のモデルを用意して、「学習」を直列的に行います。前の段階で作ったモデルの結果を参考にして、次のモデルを構築します。
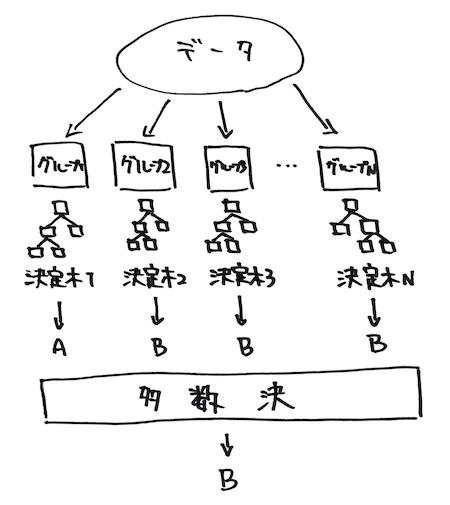
イメージで理解するランダムフォレスト¶
- ブートストラップとブースティングという考え方を元に、復元抽出した複数のデータの組を用いて異なる決定木を構築する手法です。
ランダムフォレストの実装¶
- 先ほど利用したデータを用いてランダムフォレスト実装します。
In [1]:
# データの読み込み
import pandas as pd
data = pd.read_csv("../DATA01/TALL030302.csv",index_col=0)
data.head()
Out[1]:
| sents | words | wps | ttr | score | |
|---|---|---|---|---|---|
| JPN002 | 25 | 392 | 15.680000 | 0.725000 | 3 |
| JPN004 | 18 | 288 | 16.000000 | 0.558333 | 3 |
| JPN006 | 26 | 548 | 21.076923 | 0.716667 | 5 |
| JPN008 | 21 | 332 | 15.809524 | 0.583333 | 3 |
| JPN010 | 18 | 391 | 21.722222 | 0.583333 | 3 |
In [2]:
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
# データの分割
X_train,X_test,y_train,y_test = train_test_split(data[["sents","words","wps","ttr"]],data["score"],test_size=0.2,random_state=0)
# インスタンスの生成
clf = RandomForestClassifier(random_state=1234)
# 学習
clf = clf.fit(X_train,y_train)
# 予測精度の出力
clf.score(X_test,y_test)
Out[2]:
0.56