- Wordnetには単語が以下のように保存されていると考えることができます。
言語学の一分野である意味論、あるいは、自然言語処理の一部で共有している問いのひとつとして「単語とは何か」という問いがある。
この問いは「意味とは何か」という問いと同じ意味を持つ場合がある。
| [MALE] | [FEMALE] | [ADULT] | [HUMAN] | [MARRIED] | |
|---|---|---|---|---|---|
| bachelor | + | − | + | + | − |
| spinster | − | + | + | + | − |
| woman | − | + | + | + | n.a. |
| wife | − | + | + | + | + |
| girl | − | + | − | + | − |
| boy | + | − | − | + | − |
n.a.: not applicable (設定なし)
実は、これ、認知心理学っぽい話で「カテゴリーは存在するか」という議論でもあったりする。例えば、動物を鳥と魚に分けることはできそうだけど、もっと分かりやすい例を言えば、1から100までの整数を偶数と奇数に分けることはできる。偶数のカテゴリに入るすべての整数は「2で割ると余りが0」という特徴を持っていて、奇数のカテゴリに入る全ての整数は「2で割ると余りが1」という特徴を持っている。では、「ゲーム」というカテゴリに入るものの特徴を言うことは可能でしょうか。それからプロトタイプ理論というものが出てきて...。家族的類似性とか。
上述の考え方に基づいて、単語の意味を表すために人手によって意味を定義することが考えられます。
一般には、単語の定義を記述したものを集めた辞書を参照しますが、自然言語処理ではシソーラスという辞書が使われます。
シソーラスとは類義語辞書であり、意味が似ている単語が列挙されています。
ここでは、WordNetというシソーラス兼辞書を使用します。
以下のようにimportします。
from nltk.corpus import wordnet as wn
wn.synsets("dog")
[Synset('dog.n.01'),
Synset('frump.n.01'),
Synset('dog.n.03'),
Synset('cad.n.01'),
Synset('frank.n.02'),
Synset('pawl.n.01'),
Synset('andiron.n.01'),
Synset('chase.v.01')]
dog = wn.synset("dog.n.01")
dog.definition()
'a member of the genus Canis (probably descended from the common wolf) that has been domesticated by man since prehistoric times; occurs in many breeds'
dog.examples()[0]
'the dog barked all night'
dog.lemma_names()
['dog', 'domestic_dog', 'Canis_familiaris']
wn.synset("dog.n.01").lemma_names("jpn")
['イヌ', 'ドッグ', '洋犬', '犬', '飼い犬', '飼犬']
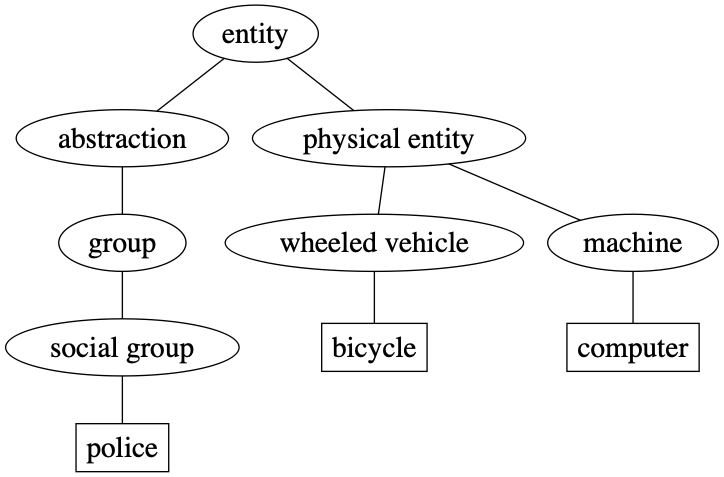
dog.hypernym_paths()
[[Synset('entity.n.01'),
Synset('physical_entity.n.01'),
Synset('object.n.01'),
Synset('whole.n.02'),
Synset('living_thing.n.01'),
Synset('organism.n.01'),
Synset('animal.n.01'),
Synset('chordate.n.01'),
Synset('vertebrate.n.01'),
Synset('mammal.n.01'),
Synset('placental.n.01'),
Synset('carnivore.n.01'),
Synset('canine.n.02'),
Synset('dog.n.01')],
[Synset('entity.n.01'),
Synset('physical_entity.n.01'),
Synset('object.n.01'),
Synset('whole.n.02'),
Synset('living_thing.n.01'),
Synset('organism.n.01'),
Synset('animal.n.01'),
Synset('domestic_animal.n.01'),
Synset('dog.n.01')]]
computer = wordnet.synset("computer.n.01")
bicycle = wordnet.synset("bicycle.n.01")
computer.path_similarity(dog)
0.09090909090909091
computer.path_similarity(bicycle)
0.14285714285714285
それぞれの文におけるballの意味を考えてみましょう。
(奥村 (2010). 『自然言語処理の基礎』より)
分布仮説を採用すると数学的なモデルが利用できる。
この、文脈に関する情報を用いて単語の意味を数量化するのが分散表現。
分散表現とは単語を数値列(ベクトル)で表現する技術。
分散表現をどのようにして得るのか実際にやってみよう。
行の単語は名詞、列の単語は動詞である。
数値は行の単語が列の単語の目的語(?)として出現する頻度である。
knifeは1列目の単語の目的語として51回出現したということである。
???の単語は何でしょう?
動詞は左から、get, see, use, hear, eat, kill
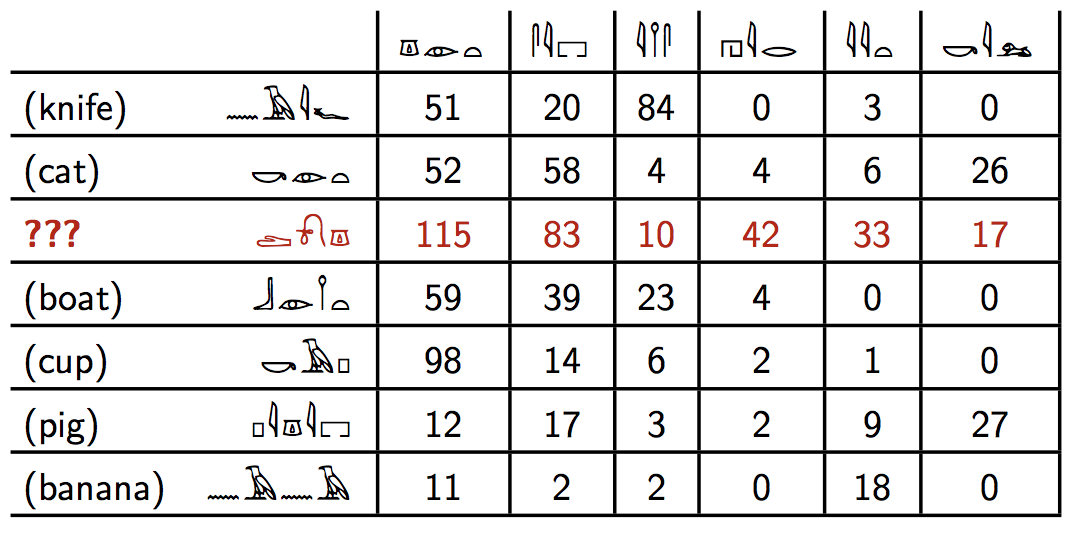
Distributional Semantic Models Tutorial at NAACL-HLT 2010より抜粋
import pandas as pd
import numpy as np
label = ["knife","cat","???","boat","cup","pig","banana"]
C = np.array([[51,20,84,0,3,0],
[52,58,4,4,6,26],
[115,83,10,42,33,17],
[59,39,23,4,0,0],
[98,14,6,2,1,0],
[12,17,3,2,9,27],
[11,2,2,0,18,0]])
C
array([[ 51, 20, 84, 0, 3, 0],
[ 52, 58, 4, 4, 6, 26],
[115, 83, 10, 42, 33, 17],
[ 59, 39, 23, 4, 0, 0],
[ 98, 14, 6, 2, 1, 0],
[ 12, 17, 3, 2, 9, 27],
[ 11, 2, 2, 0, 18, 0]])
# Standardization
C2 = []
for c in C:
sum_c = sum(c)
D = []
for c2 in c:
D.append(c2/sum_c)
C2.append(D)
pd.options.display.precision = 3
table = pd.DataFrame({"knife":C2[0],"cat":C2[1],"???":C2[2],"boat":C2[3],"cup":C2[4],"pig":C2[5],"banana":C2[6]},index=["get","see","use","hear","eat","kill"])
Decipher_hieroglyphs = table.T
Decipher_hieroglyphs
| get | see | use | hear | eat | kill | |
|---|---|---|---|---|---|---|
| knife | 0.323 | 0.127 | 0.532 | 0.000 | 0.019 | 0.000 |
| cat | 0.347 | 0.387 | 0.027 | 0.027 | 0.040 | 0.173 |
| ??? | 0.383 | 0.277 | 0.033 | 0.140 | 0.110 | 0.057 |
| boat | 0.472 | 0.312 | 0.184 | 0.032 | 0.000 | 0.000 |
| cup | 0.810 | 0.116 | 0.050 | 0.017 | 0.008 | 0.000 |
| pig | 0.171 | 0.243 | 0.043 | 0.029 | 0.129 | 0.386 |
| banana | 0.333 | 0.061 | 0.061 | 0.000 | 0.545 | 0.000 |
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
%matplotlib inline
pca = PCA(n_components=2)
X = pca.fit_transform(C2)
plt.figure(figsize=(9,6))
for i in range(len(label)):
plt.plot(X[:,0][i],X[:,1][i],"o",color="b")
plt.annotate(label[i],xy=(X[:,0][i],X[:,1][i]),fontsize=22)
