学習者言語の分析(基礎)2 第1回
1.3 簡単な自動採点システム¶
- これまで授業で扱ってきた技術を用いて自動採点システムを考えてみましょう。
In [1]:
# 使用するライブラリのimport
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
In [2]:
# データの生成
np.random.seed(100)
X1 = np.random.normal(7,5,100)
Y1 = np.random.normal(15,5,100)
X2 = np.random.normal(15,5,100)
Y2 = np.random.normal(4,4,100)
- 以下の散布図では、2つのクラスに所属しているデータが2つの変数(X軸とY軸)によって示されています。
- ここでは便宜的に青で示されたクラスを不合格(F)、オレンジで示されたクラスを合格(P)とします。
In [3]:
plt.scatter(X1,Y1,label="F")
plt.scatter(X2,Y2,label="P")
plt.legend()
Out[3]:
<matplotlib.legend.Legend at 0x151576a30>

- ここで合否がわからない新たなデータ("NEW"で示されています)を得たとします。
- このデータの合否をどのように決めることができるでしょうか。
In [4]:
plt.scatter(X1,Y1,label="F")
plt.scatter(X2,Y2,label="P")
plt.legend()
plt.scatter(7,2,marker="$NEW$",s=500)
Out[4]:
<matplotlib.collections.PathCollection at 0x1516fb250>

- Fに所属しているデータ、Pに所属しているデータすべてとの距離を算出し、平均的に近い方のクラスを新たなデータのクラスにするという決め方があります。
- ここでは、もう少し単純な方法を考えます。
- F、Pそれぞれで平均値(重心)を算出します。
- これは、それぞれのクラスで、XおよびYの平均値を算出し、それを重心の座標とします。
- 以下の図では、それぞれの重心が☆で示されています。
In [5]:
x1_ave = np.average(X1)
y1_ave = np.average(Y1)
x2_ave = np.average(X2)
y2_ave = np.average(Y2)
plt.scatter(X1,Y1,label="F")
plt.scatter(X2,Y2,label="P")
plt.scatter(x1_ave,y1_ave,marker="*",s=500,color="white",edgecolors="k")
plt.scatter(x2_ave,y2_ave,marker="*",s=500,color="white",edgecolors="k")
plt.scatter(7,2,marker="$NEW$",s=500)
plt.legend()
Out[5]:
<matplotlib.legend.Legend at 0x15200fac0>

- それぞれの重心と"NEW"の距離を算出します。
In [6]:
F_distance = np.sqrt((7 - x1_ave)**2 + (2 - y1_ave)**2)
P_distance = np.sqrt((7 - x2_ave)**2 + (2 - y2_ave)**2)
print(F_distance,P_distance)
12.659487545459246 8.8583183121659
- このデータは、Pの重心への距離が近いので「合格」と判定されます。
- これで、一応、自動採点システムは完成です。
- それでは、次に、この自動採点システムによる予測を評価してみましょう。
1.4 自動採点システムの予測精度の評価¶
- 自動採点システムを構築したのちに、新たなデータを収集し、人間による評価とシステムによる評価をそのデータに付与し、評価の一致度を計算し、評価することが最良ですが、ここでは統計学でよく用いられる交差検証という考え方に基づいて自動採点システムの予測精度を評価します。
1.4.1 交差検証法¶
- 最も簡単な交差検証法について考えます。
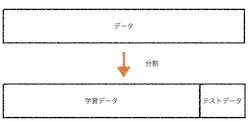
- 以下のように、現在あるデータを学習データとテストデータに分割します。
- 学習データを用いて、それぞれのクラスの平均を算出し、テストデータのxとyの値を用いて、テストデータの合否を予測します。
- 実際にテストデータの合否は分かっているので、自動採点システムによる予想と本当の合否を比較して自動採点の予測精度を計算します。
In [7]:
# 特徴量xと特徴量yをまとめます
F = []
for i,j in zip(X1,Y1):
F.append(np.array([i,j]))
P = []
for i,j in zip(X2,Y2):
P.append(np.array([i,j]))
In [8]:
# Fクラスの分割
test_F,train_F = F[:20],F[20:]
# Pクラスの分類
test_P,train_P = P[:20],P[20:]
In [9]:
# テストデータのラベルの作成
N = test_F + test_P
L = [0]*20+[1]*20
In [10]:
# それぞれのクラスで平均値を計算
x = 0
y = 0
for i,j in train_F:
x += i
y += j
F_ave = np.array([x/80,y/80])
x = 0
y = 0
for i,j in train_P:
x += i
y += j
P_ave = np.array([x/80,y/80])
- 以下の散布図では、学習データのFクラスが青、Pクラスが赤、テストデータが白抜きの○で示されています。
- この白抜きの○とそれぞれのクラスの平均値との距離を算出し、距離が近い方のクラスをそのテストデータのクラスとします。
- テストデータにおける自動採点の予測と実際の合否を比較して自動採点の予測精度を評価します。
In [11]:
plt.figure()
for i in train_F:
plt.scatter(i[0],i[1],color="b")
for i in train_P:
plt.scatter(i[0],i[1],color="r")
plt.scatter(F_ave[0],F_ave[1],marker="*",s=500,color="y",edgecolors="k")
plt.scatter(P_ave[0],P_ave[1],marker="*",s=500,color="y",edgecolors="k")
for i in N:
plt.scatter(i[0],i[1],color="None",edgecolors="k")

1.4.2 予測精度の評価指標¶
- 以下の表は自動採点の予測がどれだけ優れているかを評価するための指標を整理したものです。
| 本当\自動 | 合格 | 不合格 | |
|---|---|---|---|
| 合格 | a | b | |
| 不合格 | c | d |
この表は列が自動採点、行が本当の合否です。
- a: 本当に合格で、自動採点も合格とした人数
- b: 本当は合格なのに、自動採点は不合格とした人数
- c: 本当は不合格なのに、自動採点は合格とした人数
- d: 本当に不合格で、自動採点も合格とした人数
この人数から以下の指標を算出し、自動採点の予測精度を評価します。
正確度(Accuracy): 全体の中で正しく判定されている割合(確率) $$\frac{a+d}{a+b+c+d}$$
偽陰性率 (False negative) : 本当は合格しているのに自動採点が不合格と判定する割合(確率) (この値が高いと自動採点の方が「厳しい」と評価できる)
$$\frac{b}{a+b}$$
偽陽性率(False positive): 本当は不合格なのに自動採点が合格と判定する割合(確率)(この値が高いと自動採点が「甘い」と評価できる)
$$\frac{c}{c+d}$$
再現率(感度、真陽性率、Recall): 本当に合格した人の中で合格者を発見できる割合(確率) $$\frac{a}{a+b}$$
適合率(精度、陽性反応的中度、Precision): 自動採点が合格と判定したときに本当に合格である割合(確率) $$\frac{a}{a+c}$$
特異度(真陰性率、Specificity): 不合格の人に対して、不合格と判定する割合(確率) $$\frac{d}{c+d}$$
In [12]:
# 自動採点システムによる評価を取得
y_pred = []
for i in N:
f = np.linalg.norm(F_ave - i)
p = np.linalg.norm(P_ave - i)
if p < f:
y_pred.append(1)
else:
y_pred.append(0)
In [13]:
print(y_pred)
[0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1]
In [14]:
print(L)
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
In [15]:
D = {"a":0,"b":0,"c":0,"d":0}
for i, j in zip(L,y_pred):
if i == 1 and j == 1:
D["a"] += 1
elif i == 1 and j == 0:
D["b"] += 1
elif i == 0 and j == 1:
D["c"] += 1
else:
D["d"] += 1
In [16]:
df = pd.DataFrame({"positive":[D["a"],D["c"]],"negative":[D["b"],D["d"]]},index=["true","false"])
df
Out[16]:
| positive | negative | |
|---|---|---|
| true | 17 | 3 |
| false | 2 | 18 |
In [17]:
# 正確度
(D["a"]+D["d"])/(D["a"]+D["b"]+D["c"]+D["d"])
Out[17]:
0.875
In [18]:
# 偽陰性率(自動採点の「厳しさ」)
D["b"]/(D["a"]+D["b"])
Out[18]:
0.15
In [19]:
# 偽陽性率(自動採点の「甘さ」)
D["c"]/(D["c"]+D["d"])
Out[19]:
0.1
- 実際のデータでこれほど高い/低い値が得られることはあまりありませんが、これらの値がどの程度であれば良いかという基準もありません。
- 今回は、1回の分割で自動採点の予測精度を検証しましたが、この分割を複数回行うことで検証の妥当性を上げることができます。
練習問題¶
データを20%のテストデータと80%の学習データに分割することを100回繰り返し、それぞれの回で交差検証を行い、正確度の平均値を算出しなさい。以下のコードでリストをランダムに並べ替えることができます。
In [20]:
import random
L = [1,2,3,4,5]
L_shuffle = random.sample(L,len(L))
L_shuffle
Out[20]:
[4, 5, 2, 1, 3]