学習者言語の分析(基礎)2(第1回)
1.1 学習者言語の評価と機械学習¶
- 英語学習者のライティング技能を評価するようなテストをひとつ仮定して,このテストにおける評定者の訓練(rater training)について考えてみましょう。このテストは大規模なテストで、すでに何年も運用されていることにします。このテストの評定者に、新たな1人を加える場合を考えてみます。
1.1.1 評定者の訓練¶
- まず、評定者の候補者は、テストの仕様についてよく理解し、受験者のエッセイを実際に読み、試行的に評価をすることになります。
- 訓練に使用されるエッセイは、熟練した評定者が事前に評価をつけたものであり、現在訓練を受けている候補者の評価と熟練した評定者による評価との一致度を計算することができます。
- 候補者は自分が付与した評価と熟練した評定者が付与した評価を比較することにより、自分自身の評価に対する理解を修正します。
- この過程がある程度繰り返されたのちに、候補者には新たな作文のデータセットが与えられ、それらを評価し、熟練した評定者による評価との一致度が再度算出されます。

- 候補者と熟練した評定者間での一致度が,ある一定の基準を超えたものでなければ,この候補者はこのテストの評定者として迎えられることはないでしょう。
- 多くの場合,一度の訓練で高い一致度を示すことは困難であると考えられるので,たくさんの受験者の作文を読み,評価項目やタスクに対する理解を徐々に深めることによって,熟練した評定者との一致度が高まり,その結果として,評定者として採用されることになります。

- このように評価という行為は,十分な訓練を受けた評定者のみが行える知的行為といえます。
- この知的行為を,人間に代わってコンピュータが行えるようにするためには,どのような手順,どのようなデータがあれば可能であるのかを研究する分野が,一般に人工知能(artificial intelligence)と呼ばれる分野で,機械学習(教師あり学習) とは,これを実現する技法を指します。
1.1.2 機械学習の技法¶
コンピュータを評定者として訓練する場合も人間の評定者とまったく同じように、訓練が必要です。
人間の評定者とは異なり,コンピュータには,テストの概要や課題の内容を与えるのではなく,受験者の作文から得られる特徴量(feature) と,そのパフォーマンスに人間が付与した評価値(ラベル) を与え,しばしば特徴量と評価の関係に基づいて,評価を算出するような数理モデルを想定し,このモデルを訓練します。
ここでいう特徴量とは,評価されるライティングテキストの総語数や文法的誤りの数,1文あたりの平均単語数などをさします。たとえば,作文の総語数と文法的誤りの数を入力することによって,評価が出力されるシステムを考えることができます。
「評価が高い作文は総語数が多く,文法的誤りの数が少ない」などといった特徴量と評価値の確率的傾向を,コンピュータが学習し,評価を予測するために,何らかの計算がコンピュータ内で行われます。
人間が付与した評価ともっとも一致度が高い評価を算出する方法を見つけ,新たなデータを用いてその方法の予測精度を検証するという試行を繰り返して,人間による評価と,コンピュータによる評価の一致度がある一定の基準を超えるようになって,初めて自動採点システムは運用されます。このような過程で構築された自動採点システムは,すでに実用化されています。
このようにこれまで人間のみが行えると考えられてきた知的行為が機械学習の技法を用いることによって,コンピュータに取って代わられるようになりつつあります。
このように評定者の振る舞いを機械で再現することによって、「評定者が何をしているか」を理解することができます。このようなタイプの研究を構成論的研究と呼びます。
- ここまでの話をものすごく単純にすると以下の2次方程式を解くような問題と考えることもできる。
- 太郎さんの作文の総語数は520語、文法的誤りは7個で、佐藤先生による評価は5段階中4でした。
- 花子さんの作文の総語数は395語、文法的誤りは12個で、佐藤先生による評価は5段階中2でした。
- 佐藤先生は総語数が455語、文法的誤りが4個の作文にどの評価を与えるでしょう。

1.2 文書分類¶
- 上述した研究は自然言語処理という分野で文書分類と呼ばれています。
1.2.1 文書分類とは¶
- 文書分類とは情報科学、自然言語処理におけるタスクである。
- 文書の内容や文書に付随する情報を用いて複数の文書を2以上のカテゴリに分類する。
- 以下のような実用例がある(難波, 2016, 「人工知能による文書分類」)
- トピック分類: ニュースをスポーツ、政治、エンターテインメントなどに分類する。
- 著者推定: 著者不詳の文書の著者を推定する。
- 属性推定: 居住地、性別、年齢など著者の属性を推定する。
- 言語識別: 文書の言語を推定する。
- 評判分析: 商品、サービスのレビューが肯定的なのか否定定期なのか判定する。
- 品質評価: 人間が書いた文書の品質を自動評価する。
- フィルタリング: 送付された電子メールの重要度、あるいはスパムかどうかを判定する。
- この授業で扱うのは6. 品質評価、学習者が書いた作文の自動評価である。
1.2.2 文書分類の手順¶
- 今ある文書をカテゴリA,B,Cのいずれかに分類する以下のような場合を例とする。
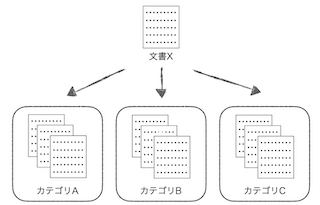
- 人手により文書をカテゴリに分ける。
- 分類された文書の特徴を抽出する。
- 文書Xから特徴を抽出する。
- 文書Xの特徴に似ている特徴を持つ文書を多く含むカテゴリに文書Xを分類する。