第3回の練習問題の解答例¶
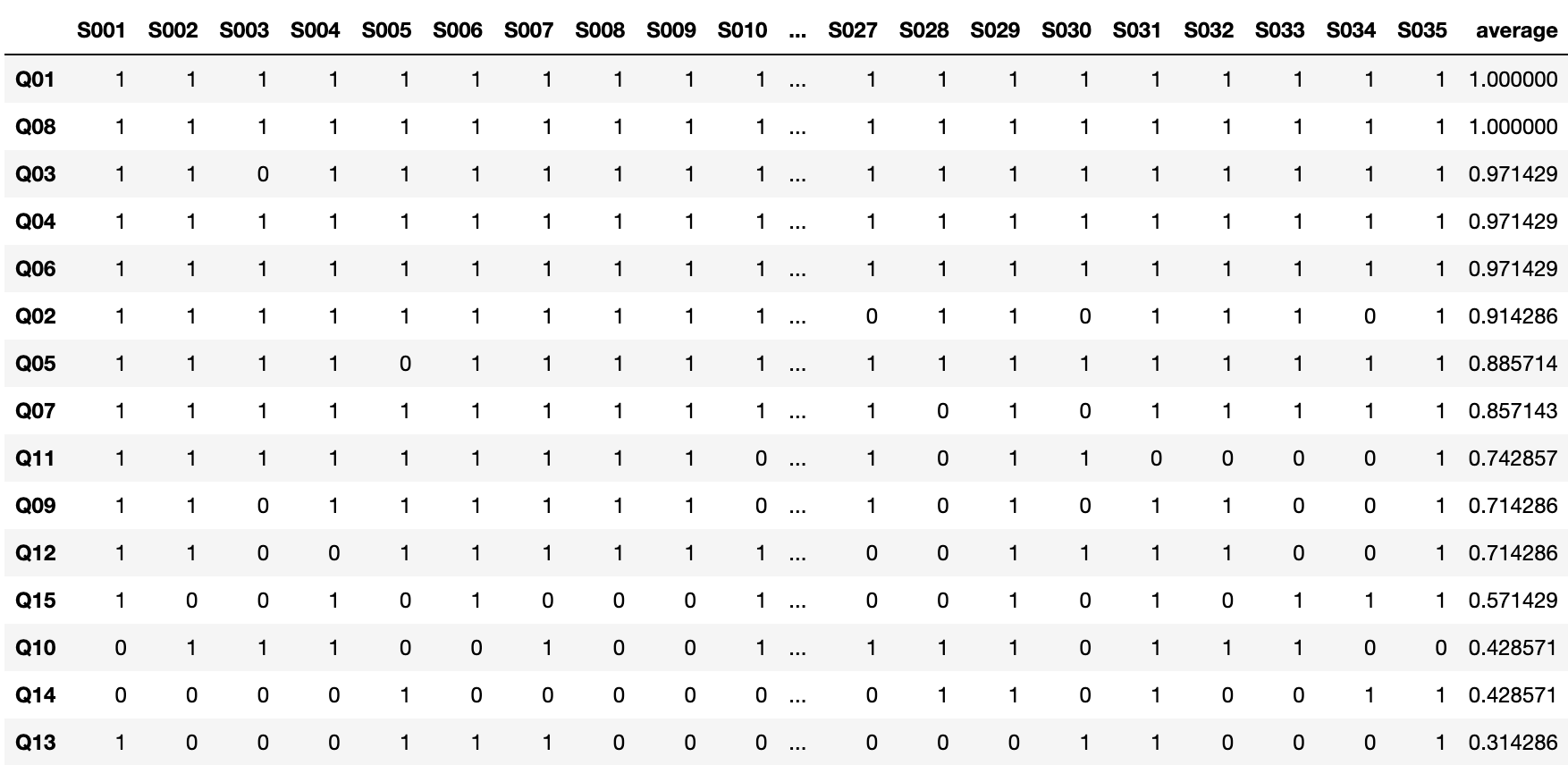
../DATA01/sample_test.csvを読み込み、項目の平均点を計算し、平均点の高い順に並べた表を出力しなさい(ちなみにこの平均値は項目困難度と呼ばれる時があります。平均値が低いほど難しい項目と言えます)。以下のようになります。
In [1]:
# pandasのimport
import pandas as pd
# csvファイルの読み込み
data = pd.read_csv("../DATA01/sample_test.csv",index_col=0)
# 欠損値の削除
data_d = data.dropna()
# 転置
data_t = data_d.T
# 平均値の算出と列名の命名
ave = data_t.mean(axis=1)
ave.name = "average"
# 結合
data_show = pd.concat([data_t,ave],axis=1)
# ソート
data_show.sort_values(by="average",ascending=False)
Out[1]:
| S001 | S002 | S003 | S004 | S005 | S006 | S007 | S008 | S009 | S010 | ... | S039 | S040 | S041 | S042 | S043 | S044 | S045 | S046 | S047 | average | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Q08 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ... | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1.000000 |
| Q01 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ... | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0.978723 |
| Q04 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ... | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0.978723 |
| Q03 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ... | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0.957447 |
| Q06 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ... | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0.957447 |
| Q05 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | ... | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0.893617 |
| Q07 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ... | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0.893617 |
| Q02 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ... | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 0.829787 |
| Q12 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | ... | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0.744681 |
| Q09 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | ... | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 0.702128 |
| Q11 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | ... | 0 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 0.702128 |
| Q15 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | ... | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 0.553191 |
| Q10 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | ... | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 0.489362 |
| Q14 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | ... | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0.404255 |
| Q13 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 0.361702 |
15 rows × 48 columns
In [ ]: