3.4 Pandasの基本操作¶
- Pythonでデータ分析に使用されるパッケージ。
- Rのdataframeのようなもの。
- PandasにはSeriesとDataFrameというデータ構造がありますが、
- 基本的にDataFrameの扱い方を学びます。
- Seriesは折に触れて。
3.4.1 ファイルの読み込み¶
In [1]:
# みなさんの学籍番号と同じ階層にある"DATA01"というディレクトリの中にある"sample_test.csv"というファイルを読み込みます。
import pandas as pd
data = pd.read_csv("../DATA01/sample_test.csv",index_col=0)
3.4.2 データの確認と要素へのアクセス¶
In [2]:
# データの確認
# head()はデータの最初の5人目までのデータを表示します。
# データが読み込まれているかどうかを確認するために使います。
data.head()
Out[2]:
| Q01 | Q02 | Q03 | Q04 | Q05 | Q06 | Q07 | Q08 | Q09 | Q10 | Q11 | Q12 | Q13 | Q14 | Q15 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S001 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 |
| S002 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 |
| S003 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 |
| S004 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 1 |
| S005 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 |
- pandasのDataFrameは以下の3つで構成されている。
- values(データ本体)
- columns(列の名前)
- index(行の名前)
In [3]:
# 下から5行も見れる
data.tail()
Out[3]:
| Q01 | Q02 | Q03 | Q04 | Q05 | Q06 | Q07 | Q08 | Q09 | Q10 | Q11 | Q12 | Q13 | Q14 | Q15 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S031 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 |
| S032 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 |
| S033 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| S034 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| S035 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
In [4]:
# 列へのアクセスは列名で
# 1列だけのデータがSeries
data["Q05"]
Out[4]:
S001 1 S002 1 S003 1 S004 1 S005 0 S006 1 S007 1 S008 1 S009 1 S010 1 S011 1 S012 0 S013 1 S014 0 S015 1 S016 1 S017 1 S018 1 S019 1 S020 1 S021 1 S022 1 S023 0 S024 1 S025 1 S026 1 S027 1 S028 1 S029 1 S030 1 S031 1 S032 1 S033 1 S034 1 S035 1 Name: Q05, dtype: int64
In [5]:
# 行へのアクセス
data.loc["S005"]
Out[5]:
Q01 1 Q02 1 Q03 1 Q04 1 Q05 0 Q06 1 Q07 1 Q08 1 Q09 1 Q10 0 Q11 1 Q12 1 Q13 1 Q14 1 Q15 0 Name: S005, dtype: int64
縦方向が列(column)、横方向が行(index)です。
In [6]:
#各要素へのアクセス
# 回答者番号"s14"の人の"item4"への回答
data.loc["S005","Q09"]
Out[6]:
1
In [7]:
# ↑と同様
data.at["S005","Q09"]
Out[7]:
1
loc[]およびat[]は行の名前、列の名前で位置を指定する。iloc[]およびiat[]は行番号、列番号で指定する。
In [8]:
data.iat[1,2]
Out[8]:
1
In [9]:
# 指定した複数要素へのアクセス
data.iloc[2:5,0:3]
Out[9]:
| Q01 | Q02 | Q03 | |
|---|---|---|---|
| S003 | 1 | 1 | 0 |
| S004 | 1 | 1 | 1 |
| S005 | 1 | 1 | 1 |
3.4.3 統計量¶
In [10]:
# 列の平均値
# それぞれの問題における正当者数の総和を解答者人数で割った値です。
data.mean()
Out[10]:
Q01 1.000000 Q02 0.914286 Q03 0.971429 Q04 0.971429 Q05 0.885714 Q06 0.971429 Q07 0.857143 Q08 1.000000 Q09 0.714286 Q10 0.428571 Q11 0.742857 Q12 0.714286 Q13 0.314286 Q14 0.428571 Q15 0.571429 dtype: float64
In [11]:
# 行の平均
# それぞれの解答者の正解数の総和を問題数で割った値です。
data.mean(axis=1)
Out[11]:
S001 0.866667 S002 0.800000 S003 0.600000 S004 0.800000 S005 0.800000 S006 0.866667 S007 0.866667 S008 0.733333 S009 0.733333 S010 0.733333 S011 0.666667 S012 0.800000 S013 0.666667 S014 0.533333 S015 0.800000 S016 0.666667 S017 0.866667 S018 0.933333 S019 0.866667 S020 0.933333 S021 0.800000 S022 0.866667 S023 0.400000 S024 0.933333 S025 0.866667 S026 0.733333 S027 0.666667 S028 0.600000 S029 0.933333 S030 0.600000 S031 0.933333 S032 0.733333 S033 0.666667 S034 0.600000 S035 0.933333 dtype: float64
In [12]:
# 表示する小数点以下の桁数を設定
# 小数点以下が多いとみにくいので
pd.options.display.precision = 2
# 基本統計量
data.describe()
# count -> データの数
# mean -> 平均値
# std -> 標準偏差
# min -> 最小値
# 25% -> 第一四分位数
# 50% -> 中央値
# 75% -> 第三四分位数
# max -> 最大値
Out[12]:
| Q01 | Q02 | Q03 | Q04 | Q05 | Q06 | Q07 | Q08 | Q09 | Q10 | Q11 | Q12 | Q13 | Q14 | Q15 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 35.0 | 35.00 | 35.00 | 35.00 | 35.00 | 35.00 | 35.00 | 35.0 | 35.00 | 35.00 | 35.00 | 35.00 | 35.00 | 35.00 | 35.00 |
| mean | 1.0 | 0.91 | 0.97 | 0.97 | 0.89 | 0.97 | 0.86 | 1.0 | 0.71 | 0.43 | 0.74 | 0.71 | 0.31 | 0.43 | 0.57 |
| std | 0.0 | 0.28 | 0.17 | 0.17 | 0.32 | 0.17 | 0.36 | 0.0 | 0.46 | 0.50 | 0.44 | 0.46 | 0.47 | 0.50 | 0.50 |
| min | 1.0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 25% | 1.0 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.0 | 0.00 | 0.00 | 0.50 | 0.00 | 0.00 | 0.00 | 0.00 |
| 50% | 1.0 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.0 | 1.00 | 0.00 | 1.00 | 1.00 | 0.00 | 0.00 | 1.00 |
| 75% | 1.0 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.0 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| max | 1.0 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.0 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
In [13]:
# 相関係数
data.corr()
Out[13]:
| Q01 | Q02 | Q03 | Q04 | Q05 | Q06 | Q07 | Q08 | Q09 | Q10 | Q11 | Q12 | Q13 | Q14 | Q15 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Q01 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| Q02 | NaN | 1.00 | -0.05 | -0.05 | -0.11 | -0.05 | 0.17 | NaN | 0.26 | 0.06 | 0.05 | 0.26 | -0.01 | 0.06 | 0.15 |
| Q03 | NaN | -0.05 | 1.00 | -0.03 | -0.06 | -0.03 | -0.07 | NaN | 0.27 | -0.20 | -0.10 | 0.27 | 0.12 | 0.15 | 0.20 |
| Q04 | NaN | -0.05 | -0.03 | 1.00 | 0.48 | -0.03 | 0.42 | NaN | 0.27 | 0.15 | 0.29 | 0.27 | 0.12 | 0.15 | -0.15 |
| Q05 | NaN | -0.11 | -0.06 | 0.48 | 1.00 | -0.06 | 0.37 | NaN | 0.17 | 0.31 | 0.20 | -0.03 | -0.34 | 0.13 | 0.05 |
| Q06 | NaN | -0.05 | -0.03 | -0.03 | -0.06 | 1.00 | -0.07 | NaN | -0.11 | 0.15 | -0.10 | -0.11 | 0.12 | 0.15 | 0.20 |
| Q07 | NaN | 0.17 | -0.07 | 0.42 | 0.37 | -0.07 | 1.00 | NaN | 0.46 | 0.19 | 0.32 | 0.28 | -0.08 | 0.02 | 0.14 |
| Q08 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| Q09 | NaN | 0.26 | 0.27 | 0.27 | 0.17 | -0.11 | 0.46 | NaN | 1.00 | 0.04 | 0.50 | 0.58 | 0.16 | 0.29 | -0.04 |
| Q10 | NaN | 0.06 | -0.20 | 0.15 | 0.31 | 0.15 | 0.19 | NaN | 0.04 | 1.00 | -0.28 | -0.09 | -0.34 | 0.07 | -0.30 |
| Q11 | NaN | 0.05 | -0.10 | 0.29 | 0.20 | -0.10 | 0.32 | NaN | 0.50 | -0.28 | 1.00 | 0.21 | 0.12 | -0.02 | 0.02 |
| Q12 | NaN | 0.26 | 0.27 | 0.27 | -0.03 | -0.11 | 0.28 | NaN | 0.58 | -0.09 | 0.21 | 1.00 | 0.43 | 0.16 | -0.16 |
| Q13 | NaN | -0.01 | 0.12 | 0.12 | -0.34 | 0.12 | -0.08 | NaN | 0.16 | -0.34 | 0.12 | 0.43 | 1.00 | 0.04 | 0.09 |
| Q14 | NaN | 0.06 | 0.15 | 0.15 | 0.13 | 0.15 | 0.02 | NaN | 0.29 | 0.07 | -0.02 | 0.16 | 0.04 | 1.00 | 0.17 |
| Q15 | NaN | 0.15 | 0.20 | -0.15 | 0.05 | 0.20 | 0.14 | NaN | -0.04 | -0.30 | 0.02 | -0.16 | 0.09 | 0.17 | 1.00 |
- この相関係数は項目間相関と呼ばれ、
- 項目がどのような振る舞いをしているかを示す指標と考えることができます。
- テストやアンケートはひとつの能力などを測定しているということを前提としています。
- そのため、他の項目との相関係数が低い場合、「その項目はテストで測定しようとしている能力を測定していない」と考えることができます。
3.4.4 条件指定¶
In [14]:
# 条件指定: item1が4より小さい行
data[data["Q15"] == 1]
Out[14]:
| Q01 | Q02 | Q03 | Q04 | Q05 | Q06 | Q07 | Q08 | Q09 | Q10 | Q11 | Q12 | Q13 | Q14 | Q15 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S001 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 |
| S004 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 1 |
| S006 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 |
| S010 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 |
| S011 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| S012 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 |
| S016 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| S017 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 |
| S018 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 |
| S020 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
| S021 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 1 |
| S022 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 |
| S023 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| S024 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
| S026 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 |
| S029 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 |
| S031 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 |
| S033 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| S034 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| S035 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
In [15]:
# 複数条件指定: Q12とQ10ともに正解の人
# &, |, ~を使う
data[(data["Q12"] == 1) & (data["Q10"] == 1)]
Out[15]:
| Q01 | Q02 | Q03 | Q04 | Q05 | Q06 | Q07 | Q08 | Q09 | Q10 | Q11 | Q12 | Q13 | Q14 | Q15 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S002 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 |
| S007 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 |
| S010 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 |
| S015 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 |
| S018 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 |
| S019 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 |
| S025 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 |
| S029 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 |
| S031 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 |
| S032 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 |
| 記号 | 意味 |
|---|---|
| & (and) | 論理積(両方がTrue) |
| | (or) | 論理和(どちらかがTrue) |
| ~ (not) | 否定 |
3.4.5 ソート¶
In [16]:
# Q12の値でソート(昇順)
data.sort_values(by ="Q12")
Out[16]:
| Q01 | Q02 | Q03 | Q04 | Q05 | Q06 | Q07 | Q08 | Q09 | Q10 | Q11 | Q12 | Q13 | Q14 | Q15 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S027 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 |
| S033 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| S003 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 |
| S004 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 1 |
| S016 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| S023 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| S028 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| S034 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| S011 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| S026 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 |
| S022 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 |
| S024 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
| S001 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 |
| S029 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 |
| S030 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 1 | 0 | 0 |
| S031 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 |
| S032 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 |
| S025 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 |
| S021 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 1 |
| S018 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 |
| S019 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 |
| S017 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 |
| S015 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 |
| S014 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 |
| S013 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 |
| S012 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 |
| S010 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 |
| S009 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 |
| S008 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 |
| S007 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 |
| S006 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 |
| S005 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 |
| S002 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 |
| S020 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
| S035 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
In [17]:
# Q12の値でソート(降順)
data.sort_values(by ="Q12",ascending=False)
Out[17]:
| Q01 | Q02 | Q03 | Q04 | Q05 | Q06 | Q07 | Q08 | Q09 | Q10 | Q11 | Q12 | Q13 | Q14 | Q15 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S001 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 |
| S015 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 |
| S032 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 |
| S031 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 |
| S030 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 1 | 0 | 0 |
| S029 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 |
| S025 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 |
| S024 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
| S022 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 |
| S021 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 1 |
| S020 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
| S019 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 |
| S002 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 |
| S017 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 |
| S018 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 |
| S035 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
| S005 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 |
| S013 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 |
| S012 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 |
| S010 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 |
| S009 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 |
| S008 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 |
| S007 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 |
| S014 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 |
| S006 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 |
| S034 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| S033 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| S003 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 |
| S004 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 1 |
| S016 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| S028 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| S027 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 |
| S023 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| S011 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| S026 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 |
3.4.6 転置¶
In [18]:
# 転置(行と列を入れ替える)
data.T
Out[18]:
| S001 | S002 | S003 | S004 | S005 | S006 | S007 | S008 | S009 | S010 | ... | S026 | S027 | S028 | S029 | S030 | S031 | S032 | S033 | S034 | S035 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Q01 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ... | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Q02 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ... | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 |
| Q03 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ... | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Q04 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ... | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Q05 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | ... | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Q06 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ... | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Q07 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ... | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
| Q08 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ... | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Q09 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | ... | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 1 |
| Q10 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | ... | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 0 |
| Q11 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | ... | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 |
| Q12 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | ... | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 1 |
| Q13 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 1 |
| Q14 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | ... | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 |
| Q15 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | ... | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 1 |
15 rows × 35 columns
3.4.7 データフレームの作成¶
In [19]:
# DataFrameを作る
data2 = pd.DataFrame({"evaluation":[0,0,0,0,0,0,0,0,1,0,0,1,1,1,1,1,1,0,1,1],
"grade":[1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,2,2,2,3,4]})
data2.head()
Out[19]:
| evaluation | grade | |
|---|---|---|
| 0 | 0 | 1 |
| 1 | 0 | 1 |
| 2 | 0 | 1 |
| 3 | 0 | 1 |
| 4 | 0 | 1 |
3.4.8 特定の列、行の削除¶
In [20]:
# 特定の列を削除(非破壊)
data.drop("Q01",axis=1)
Out[20]:
| Q02 | Q03 | Q04 | Q05 | Q06 | Q07 | Q08 | Q09 | Q10 | Q11 | Q12 | Q13 | Q14 | Q15 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S001 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 |
| S002 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 |
| S003 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 |
| S004 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 1 |
| S005 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 |
| S006 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 |
| S007 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 |
| S008 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 |
| S009 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 |
| S010 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 |
| S011 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| S012 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 |
| S013 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 |
| S014 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 |
| S015 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 |
| S016 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| S017 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 |
| S018 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 |
| S019 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 |
| S020 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
| S021 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 1 |
| S022 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 |
| S023 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| S024 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
| S025 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 |
| S026 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 |
| S027 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 |
| S028 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| S029 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 |
| S030 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 1 | 0 | 0 |
| S031 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 |
| S032 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 |
| S033 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| S034 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| S035 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
In [21]:
# 特定の列を削除(破壊)
# 出力はない
del data["Q01"]
In [22]:
# 特定の列を削除(非破壊)
data.drop("S001")
Out[22]:
| Q02 | Q03 | Q04 | Q05 | Q06 | Q07 | Q08 | Q09 | Q10 | Q11 | Q12 | Q13 | Q14 | Q15 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S002 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 |
| S003 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 |
| S004 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 1 |
| S005 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 |
| S006 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 |
| S007 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 |
| S008 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 |
| S009 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 |
| S010 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 |
| S011 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| S012 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 |
| S013 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 |
| S014 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 |
| S015 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 |
| S016 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| S017 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 |
| S018 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 |
| S019 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 |
| S020 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
| S021 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 1 |
| S022 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 |
| S023 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| S024 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
| S025 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 |
| S026 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 |
| S027 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 |
| S028 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| S029 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 |
| S030 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 1 | 0 | 0 |
| S031 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 |
| S032 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 |
| S033 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| S034 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| S035 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
In [23]:
# 特定の行を削除(非破壊)(複数)
data.drop(["S001","S002","S003"])
Out[23]:
| Q02 | Q03 | Q04 | Q05 | Q06 | Q07 | Q08 | Q09 | Q10 | Q11 | Q12 | Q13 | Q14 | Q15 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S004 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 1 |
| S005 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 |
| S006 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 |
| S007 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 |
| S008 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 |
| S009 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 |
| S010 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 |
| S011 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| S012 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 |
| S013 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 |
| S014 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 |
| S015 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 |
| S016 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| S017 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 |
| S018 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 |
| S019 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 |
| S020 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
| S021 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 1 |
| S022 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 |
| S023 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| S024 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
| S025 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 |
| S026 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 |
| S027 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 |
| S028 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| S029 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 |
| S030 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 1 | 0 | 0 |
| S031 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 |
| S032 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 |
| S033 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| S034 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| S035 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
3.4.9 データフレームの出力¶
In [24]:
# csvへ出力
data.to_csv("data_c.csv")
3.4.10 その他のメソッド¶
| メソッド | 意味 |
|---|---|
| len(data) | 行数 |
| data.shape | 行数と列数タプル |
| data.columns | 列名 |
| data.index | 行名 |
| data.sum() | 合計 |
| data.info() | 列名とその型の一覧 |
| data.std() | 標準偏差 |
| data.quantile() | 中央値 |
| data.count() | データの個数 |
3.4.11 欠損値の取り扱い¶
In [26]:
# 欠損値のあるデータの読み込み
data = pd.read_csv("../DATA01/IEDA03_1.csv",index_col=0)
data
Out[26]:
| item1 | item2 | item3 | item4 | item5 | item6 | item7 | item8 | |
|---|---|---|---|---|---|---|---|---|
| s01 | 5 | 4 | 4.0 | 5.0 | 4 | 4 | 6.0 | 5 |
| s02 | 4 | 3 | 1.0 | 3.0 | 3 | 3 | 2.0 | 4 |
| s03 | 4 | 4 | 3.0 | 3.0 | 3 | 3 | 3.0 | 3 |
| s04 | 5 | 3 | 3.0 | 3.0 | 3 | 4 | 3.0 | 3 |
| s05 | 3 | 2 | 3.0 | 3.0 | 3 | 3 | 3.0 | 3 |
| s06 | 2 | 3 | 2.0 | 1.0 | 1 | 1 | 2.0 | 2 |
| s07 | 4 | 4 | 4.0 | NaN | 3 | 4 | NaN | 4 |
| s08 | 3 | 2 | 2.0 | 3.0 | 2 | 3 | 2.0 | 2 |
| s09 | 3 | 2 | 2.0 | 2.0 | 1 | 1 | 1.0 | 1 |
| s10 | 4 | 4 | 4.0 | 3.0 | 4 | 4 | 3.0 | 3 |
| s11 | 4 | 3 | 2.0 | 2.0 | 2 | 2 | 2.0 | 3 |
| s12 | 6 | 6 | 6.0 | 6.0 | 6 | 6 | 6.0 | 6 |
| s13 | 4 | 4 | 5.0 | 4.0 | 3 | 3 | 4.0 | 3 |
| s14 | 5 | 5 | 5.0 | 5.0 | 5 | 5 | 5.0 | 4 |
| s15 | 6 | 6 | 6.0 | 6.0 | 6 | 6 | 6.0 | 6 |
| s16 | 5 | 5 | 5.0 | 4.0 | 5 | 4 | 4.0 | 3 |
| s17 | 4 | 3 | 3.0 | 4.0 | 4 | 4 | 3.0 | 3 |
| s18 | 2 | 1 | NaN | 1.0 | 1 | 2 | 5.0 | 5 |
| s19 | 4 | 3 | 3.0 | 4.0 | 3 | 3 | 2.0 | 2 |
| s20 | 6 | 6 | 6.0 | 6.0 | 6 | 6 | 6.0 | 6 |
In [27]:
# 欠損値が含まれている行を削除
data.dropna()
Out[27]:
| item1 | item2 | item3 | item4 | item5 | item6 | item7 | item8 | |
|---|---|---|---|---|---|---|---|---|
| s01 | 5 | 4 | 4.0 | 5.0 | 4 | 4 | 6.0 | 5 |
| s02 | 4 | 3 | 1.0 | 3.0 | 3 | 3 | 2.0 | 4 |
| s03 | 4 | 4 | 3.0 | 3.0 | 3 | 3 | 3.0 | 3 |
| s04 | 5 | 3 | 3.0 | 3.0 | 3 | 4 | 3.0 | 3 |
| s05 | 3 | 2 | 3.0 | 3.0 | 3 | 3 | 3.0 | 3 |
| s06 | 2 | 3 | 2.0 | 1.0 | 1 | 1 | 2.0 | 2 |
| s08 | 3 | 2 | 2.0 | 3.0 | 2 | 3 | 2.0 | 2 |
| s09 | 3 | 2 | 2.0 | 2.0 | 1 | 1 | 1.0 | 1 |
| s10 | 4 | 4 | 4.0 | 3.0 | 4 | 4 | 3.0 | 3 |
| s11 | 4 | 3 | 2.0 | 2.0 | 2 | 2 | 2.0 | 3 |
| s12 | 6 | 6 | 6.0 | 6.0 | 6 | 6 | 6.0 | 6 |
| s13 | 4 | 4 | 5.0 | 4.0 | 3 | 3 | 4.0 | 3 |
| s14 | 5 | 5 | 5.0 | 5.0 | 5 | 5 | 5.0 | 4 |
| s15 | 6 | 6 | 6.0 | 6.0 | 6 | 6 | 6.0 | 6 |
| s16 | 5 | 5 | 5.0 | 4.0 | 5 | 4 | 4.0 | 3 |
| s17 | 4 | 3 | 3.0 | 4.0 | 4 | 4 | 3.0 | 3 |
| s19 | 4 | 3 | 3.0 | 4.0 | 3 | 3 | 2.0 | 2 |
| s20 | 6 | 6 | 6.0 | 6.0 | 6 | 6 | 6.0 | 6 |
In [28]:
# 欠損値を0で埋める
data.fillna(0)
Out[28]:
| item1 | item2 | item3 | item4 | item5 | item6 | item7 | item8 | |
|---|---|---|---|---|---|---|---|---|
| s01 | 5 | 4 | 4.0 | 5.0 | 4 | 4 | 6.0 | 5 |
| s02 | 4 | 3 | 1.0 | 3.0 | 3 | 3 | 2.0 | 4 |
| s03 | 4 | 4 | 3.0 | 3.0 | 3 | 3 | 3.0 | 3 |
| s04 | 5 | 3 | 3.0 | 3.0 | 3 | 4 | 3.0 | 3 |
| s05 | 3 | 2 | 3.0 | 3.0 | 3 | 3 | 3.0 | 3 |
| s06 | 2 | 3 | 2.0 | 1.0 | 1 | 1 | 2.0 | 2 |
| s07 | 4 | 4 | 4.0 | 0.0 | 3 | 4 | 0.0 | 4 |
| s08 | 3 | 2 | 2.0 | 3.0 | 2 | 3 | 2.0 | 2 |
| s09 | 3 | 2 | 2.0 | 2.0 | 1 | 1 | 1.0 | 1 |
| s10 | 4 | 4 | 4.0 | 3.0 | 4 | 4 | 3.0 | 3 |
| s11 | 4 | 3 | 2.0 | 2.0 | 2 | 2 | 2.0 | 3 |
| s12 | 6 | 6 | 6.0 | 6.0 | 6 | 6 | 6.0 | 6 |
| s13 | 4 | 4 | 5.0 | 4.0 | 3 | 3 | 4.0 | 3 |
| s14 | 5 | 5 | 5.0 | 5.0 | 5 | 5 | 5.0 | 4 |
| s15 | 6 | 6 | 6.0 | 6.0 | 6 | 6 | 6.0 | 6 |
| s16 | 5 | 5 | 5.0 | 4.0 | 5 | 4 | 4.0 | 3 |
| s17 | 4 | 3 | 3.0 | 4.0 | 4 | 4 | 3.0 | 3 |
| s18 | 2 | 1 | 0.0 | 1.0 | 1 | 2 | 5.0 | 5 |
| s19 | 4 | 3 | 3.0 | 4.0 | 3 | 3 | 2.0 | 2 |
| s20 | 6 | 6 | 6.0 | 6.0 | 6 | 6 | 6.0 | 6 |
3.4.12 演算¶
In [29]:
# item1だけ値を3倍して出力
data["item1"] * 3
Out[29]:
s01 15 s02 12 s03 12 s04 15 s05 9 s06 6 s07 12 s08 9 s09 9 s10 12 s11 12 s12 18 s13 12 s14 15 s15 18 s16 15 s17 12 s18 6 s19 12 s20 18 Name: item1, dtype: int64
In [30]:
# item1の値を3倍した値に変更する
data["item1"] = data["item1"] * 3
data.head()
Out[30]:
| item1 | item2 | item3 | item4 | item5 | item6 | item7 | item8 | |
|---|---|---|---|---|---|---|---|---|
| s01 | 15 | 4 | 4.0 | 5.0 | 4 | 4 | 6.0 | 5 |
| s02 | 12 | 3 | 1.0 | 3.0 | 3 | 3 | 2.0 | 4 |
| s03 | 12 | 4 | 3.0 | 3.0 | 3 | 3 | 3.0 | 3 |
| s04 | 15 | 3 | 3.0 | 3.0 | 3 | 4 | 3.0 | 3 |
| s05 | 9 | 2 | 3.0 | 3.0 | 3 | 3 | 3.0 | 3 |
In [32]:
# 読み込み直して
data = pd.read_csv("../DATA01/IEDA03_1.csv",index_col=0)
# 合計の列を追加
data["average"] = data.mean(axis=1)
data.head()
Out[32]:
| item1 | item2 | item3 | item4 | item5 | item6 | item7 | item8 | average | |
|---|---|---|---|---|---|---|---|---|---|
| s01 | 5 | 4 | 4.0 | 5.0 | 4 | 4 | 6.0 | 5 | 4.62 |
| s02 | 4 | 3 | 1.0 | 3.0 | 3 | 3 | 2.0 | 4 | 2.88 |
| s03 | 4 | 4 | 3.0 | 3.0 | 3 | 3 | 3.0 | 3 | 3.25 |
| s04 | 5 | 3 | 3.0 | 3.0 | 3 | 4 | 3.0 | 3 | 3.38 |
| s05 | 3 | 2 | 3.0 | 3.0 | 3 | 3 | 3.0 | 3 | 2.88 |
In [33]:
# 個人の合計得点の列を追加
data["sum"] = data.iloc[:,0:8].sum(axis=1)
data.head()
Out[33]:
| item1 | item2 | item3 | item4 | item5 | item6 | item7 | item8 | average | sum | |
|---|---|---|---|---|---|---|---|---|---|---|
| s01 | 5 | 4 | 4.0 | 5.0 | 4 | 4 | 6.0 | 5 | 4.62 | 37.0 |
| s02 | 4 | 3 | 1.0 | 3.0 | 3 | 3 | 2.0 | 4 | 2.88 | 23.0 |
| s03 | 4 | 4 | 3.0 | 3.0 | 3 | 3 | 3.0 | 3 | 3.25 | 26.0 |
| s04 | 5 | 3 | 3.0 | 3.0 | 3 | 4 | 3.0 | 3 | 3.38 | 27.0 |
| s05 | 3 | 2 | 3.0 | 3.0 | 3 | 3 | 3.0 | 3 | 2.88 | 23.0 |
In [34]:
# 個人の得点と平均値の差の列を追加
data["diff"] = data["sum"] - data.iloc[:,0:8].sum(axis=1).mean()
data.head()
Out[34]:
| item1 | item2 | item3 | item4 | item5 | item6 | item7 | item8 | average | sum | diff | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| s01 | 5 | 4 | 4.0 | 5.0 | 4 | 4 | 6.0 | 5 | 4.62 | 37.0 | 8.45 |
| s02 | 4 | 3 | 1.0 | 3.0 | 3 | 3 | 2.0 | 4 | 2.88 | 23.0 | -5.55 |
| s03 | 4 | 4 | 3.0 | 3.0 | 3 | 3 | 3.0 | 3 | 3.25 | 26.0 | -2.55 |
| s04 | 5 | 3 | 3.0 | 3.0 | 3 | 4 | 3.0 | 3 | 3.38 | 27.0 | -1.55 |
| s05 | 3 | 2 | 3.0 | 3.0 | 3 | 3 | 3.0 | 3 | 2.88 | 23.0 | -5.55 |
練習問題¶
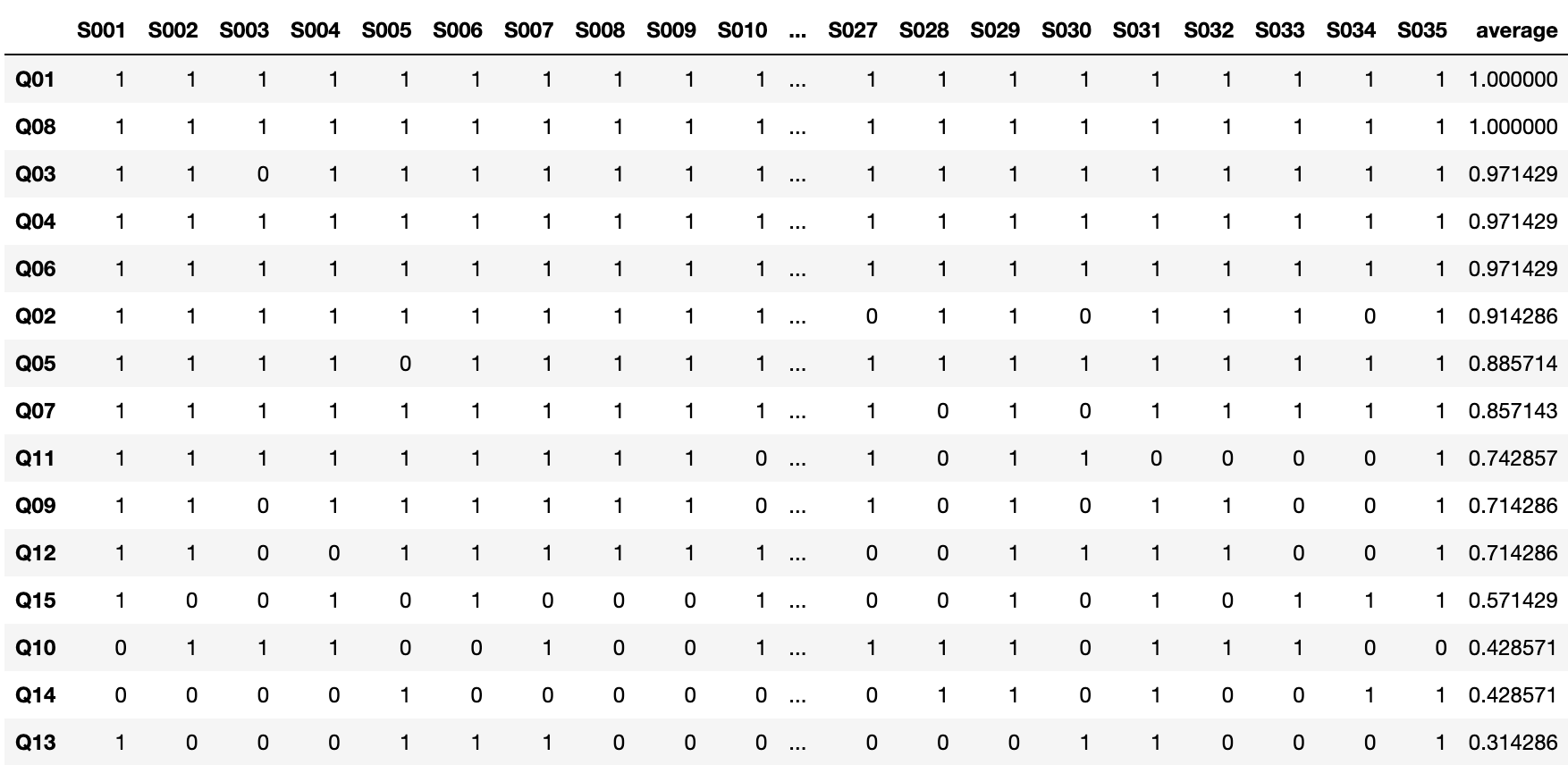
"../DATA01/sample_test.csv"を読み込み、項目の平均点を計算し、平均点の高い順に並べた表を出力しなさい(ちなみにこの平均値は項目困難度と呼ばれる時があります。平均値が低いほど難しい項目と言えます)。以下のようになります。